
Tamanho Amostral: Regressão Logística Binária








Aprenda a calcular o tamanho da amostra para Regressão Logística Binária Simples utilizando o software GPower, além de entender as nuances dos parâmetros e como garantir a precisão em seus cálculos.
Neste artigo vamos mostrar como calcular o tamanho amostral para uma Regressão Logística Binária Simples.
Para isso, utilizaremos o software gratuito G*Power, que é um dos mais utilizados para este fim.
Nosso estímulo para este artigo foi que absolutamente todos os tutoriais que encontramos na internet ensinando a execução deste cálculo no G*Power estão imprecisos.
Após baixar e instalar o G*Power, vamos abri-lo e selecionar a opção de cálculo de tamanho amostral para a análise de regressão logística clicando na aba Tests: Correlation and regression: Logistic regression.
Agora temos que preencher os parâmetros de entrada:
Em Tail(s), marque One se o teste for unicaudal ou Two se o teste for bicaudal.
O teste será unicaudal quando tivermos uma hipótese alternativa específica, por exemplo, “quanto maior o valor de X, maior a probabilidade de ocorrência do eventoy”, ou vice-versa.
E o teste será bicaudal quando tivermos uma hipótese alternativa geral, por exemplo, “X influencia no evento y“, ou seja, sem distinção inicial da direção.
Essa hipótese deve ser baseada em conhecimento existente na área de estudo. Se não tem certeza, melhor manter a opção Two (Bicaudal).
Aqui, temos o nível de significância (alfa), que é a probabilidade de rejeição da hipótese nula quando ela é verdadeira (ou seja, a probabilidade de cometermos o erro tipo I).
Normalmente utiliza-se 0,05 ou 0,01. Um α = 0,05, por exemplo, indica um risco de 5% de concluir que há uma relação significativa na relação quando na realidade essa relação não existe.
Aqui, temos o Poder do Teste (1 – β), que é a probabilidade de rejeitar a hipótese nula se realmente for falsa, ou seja, o quanto o teste controla o erro tipo II (β).
Normalmente um valor aceitável está entre 0,80 e 0,99. Quanto maior o poder do teste, melhor, mas à medida que o aumentamos, o tamanho amostral requerido também aumenta.
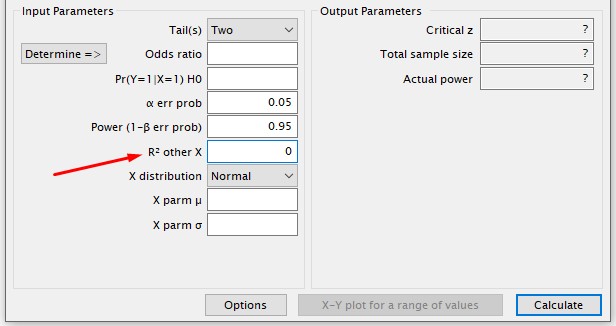
Nesse parâmetro, que é o R-quadrado das outras variáveis X, para modelos de regressão logística binária simples, ou seja, que possuem somente uma variável independente, basta mantermos o valor em zero.
Aqui selecionamos o tipo de Distribuição da variável X, que é a variável independente ou preditora do modelo.
Se for binária, assim como a variável dependente (y) é, devemos selecionar a opção Binomial. Normalmente, se for quantitativa contínua, selecionamos a opção Normal. Se for quantitativa discreta, podemos selecionar a opção Poisson. As outras distribuições disponíveis só devem ser utilizadas se houver razão para tal.
OK, agora os quatro últimos parâmetros que devemos entrar são estimativas da população, que devemos obter por meio de coleta piloto, ou a partir de dados de estudos semelhantes, ou até de estimativas teóricas.
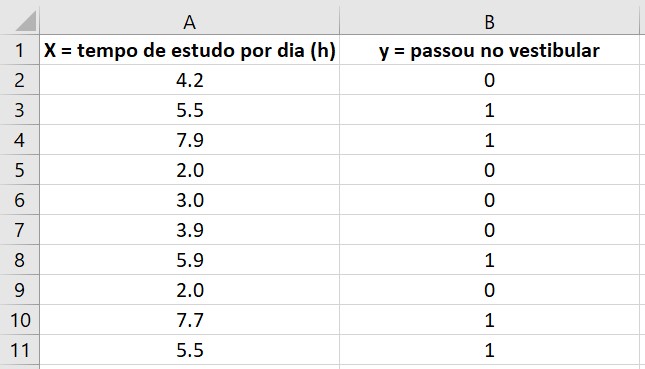
Na maioria das vezes, se possível, é melhor utilizar dados de coleta piloto, que é o que faremos aqui.
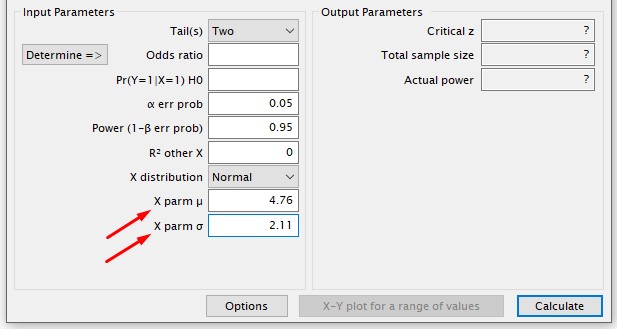
Para este parâmetro, Média populacional da variável X, que é a estimativa da média populacional da variável independente (X), basta calcular a média da variável X dos dados da coleta piloto.
Este outro parâmetro, Desvio padrão populacional da variável X, que é a estimativa do desvio padrão populacional da variável independente (X), basta calcular o desvio padrão da variável X dos dados da coleta piloto.
Obteremos os dois últimos a partir de uma análise de regressão logística simples preliminar com os dados da coleta piloto.
Para a demonstração, utilizaremos o software BioEstat, que é um software bem simples e gratuito. Você pode utilizar qualquer outro programa que rode a regressão logística.
O odds ratio ou razão de chances representa uma medida de associação entre uma exposição e um desfecho, uma medida de tamanho do efeito.
Então, fizemos uma análise preliminar com os dados da coleta piloto no BioEstat para obtermos este valor do odds ratio. Devemos digitá-lo no G*Power.
O último parâmetro, é a Probabilidade de ocorrência da variável dependente (y = 1) quando a hipótese nula (H0) é verdadeira, ou seja, quando o coeficiente da variável independente (X) é igual a 0 e no modelo consta somente o intercepto.
Este valor pode ser obtido da seguinte forma no BioEstat. Faça a análise preliminar, clique em Exibir a Estimação de Y, digite zero em Valor de X1, e então clique em Estimar Y. Este é o valor que precisamos preencher no G*Power.
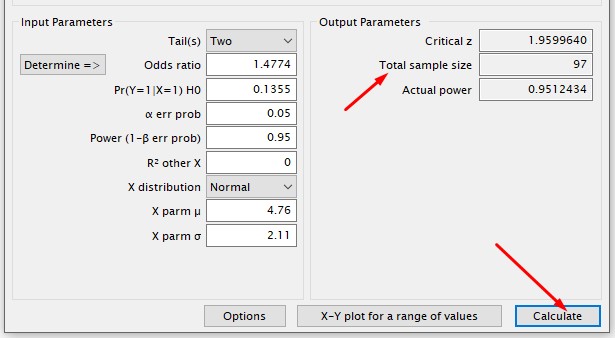
Com todos parâmetros preenchidos no G*Power, agora basta clicar em Calculate para obtermos o tamanho amostral definido pelo cálculo!
Nesse exemplo o tamanho amostral requerido para identificar o odds ratio estimado foi de 97 indivíduos amostrados aleatoriamente da população alvo.
ATUALIZAÇÃO:
Quer aprender a calcular o tamanho amostral no G*Power para outras análises inferenciais mais importantes?
Então, baixe gratuitamente as amostras do nosso livro digital lançado recentemente.
Lá você aprenderá a calcular o tamanho amostral para o teste t para amostras independentes ou pareadas; anova de uma ou duas vias, para medidas repetidas ou não, e modelo misto; regressão linear e logística simples e múltipla, etc.
Clique neste link e saiba mais sobre ele: Estatística Aplicada: Análise de Dados.

Explore a possibilidade de o coeficiente de correlação ser negativo e conheça suas aplicações em setores como finanças, medicina e esportes.

Entenda a diferença entre correlação vs. causalidade na análise de dados e aprenda como evitar armadilhas comuns e equívocos.

Aprenda como evitar erros comuns na ANOVA de um fator, para que sua pesquisa apresente uma análise precisa e conclusões válidas.

Você aprenderá como calcular o tamanho amostral para o Teste t de Student de forma eficiente e prática, otimizando tempo e recursos. Instagram Facebook Youtube Pinterest Wordpress Você sabia que o cálculo do tamanho amostral é um passo importantíssimo de uma análise e que ele economiza seu tempo e dinheiro? Sabia que um tamanho amostral adequado aos…

Explore as Premissas da Regressão Logística, aprenda sobre seus diferentes tipos e entenda as premissas vitais para análises precisas.

Descubra como estimar o tamanho de efeito para o cálculo de tamanho amostral no G*Power, equilibrando aspectos estatísticos e práticos.
Se a variável independente for qualitativa nominal não será possível calcular a média e desvio padrão. Como calcular a amostra para a regressão logística simples nessa situação?
Olá, Rosana! Basta você alterar a opção Distribuição da Variável X (X distribution) para o tipo/distribuição da sua variável.